인간 피드백을 통한 강화학습 RLHF, Reinforcement Learning from Human Feedback

[ RLHF, Reinforcement Learning from Human Feedback ]
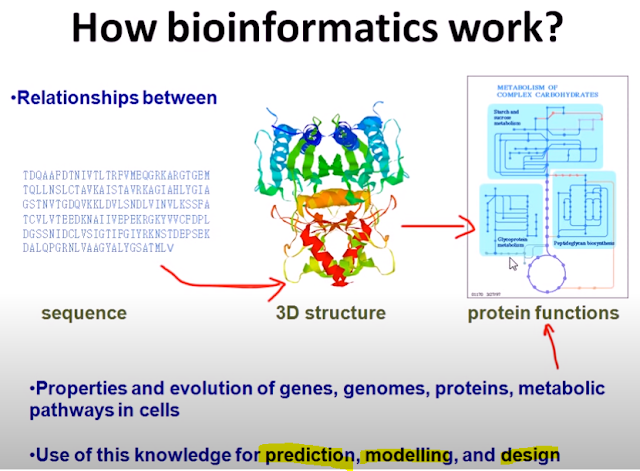
● 강화학습(Reinforcement Learning)
- 학습 데이터가 주어진 상태에서 변화가 없는 정적인 환경에서 진행되는 지도 학습이나 비지도 학습과 달리 불확실한 환경과 상호작용을 통해 주어진 업무를 학습
- 어떤 환경 안에서 정의된 주체(agent)가 현재의 상태를 관찰하며 선택할 수 있는 행동(action) 중 최대의 보상(reward)을 가져다주는 행동이 무엇인지 학습
● 강화학습의 동작 순서
- 정의된 주체(agent)가 주어진 환경(environment)의 현재 상태(state)를 관찰(observation)하여, 행동 (action) 수행 → 환경의 상태가 변화하면서 정의된 주체에게 보상(reward) → 보상을 기반으로 정의된 주체는 더 많은 보상을 얻을 수 있는 방향(best action)으로 행동 학습
● 인간 피드백을 통한 강화학습(RLHF, Reinforcement Learning from Human Feedback)
- 사람의 피드백(Human Feedback)을 통해 강화학습을 시킬 경우 인간적인 말투, 문화적인 요소 등을 반영할 수 있는데 ChatGPT는 RLHF를 적용함으로써 인간과 구별할 수 없을 정도로 자연스러운 문장 구사 가능
[ 출처 : NIA "ChatGPT는 혁신의 도구가 될 수 있을까? : ChatGPT 활용 사례 및 전망" 중 ]
댓글
댓글 쓰기