[딥러닝을이용한 자연어 처리 입문] 1501 시퀀스-투-시퀀스(Sequence-to-Sequence, seq2seq)

1. 시퀀스-투-시퀀스(Sequence-to-Sequence)
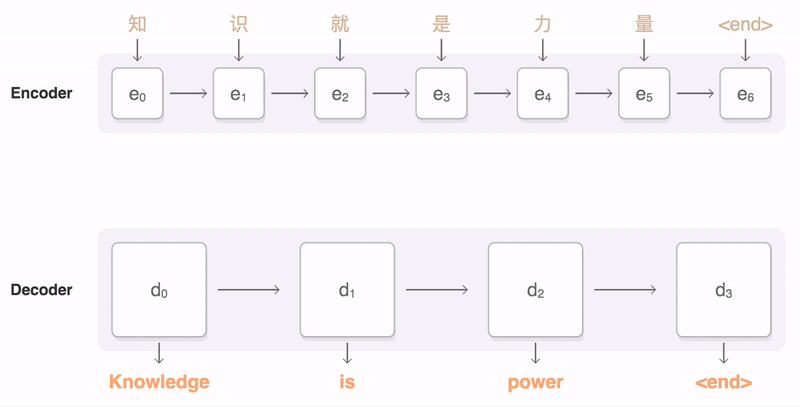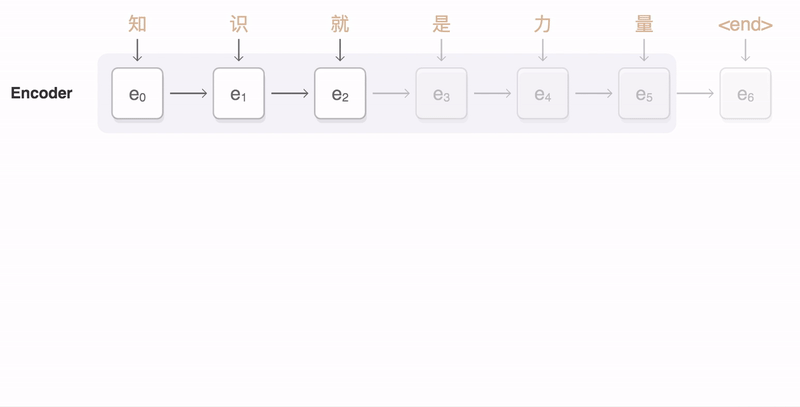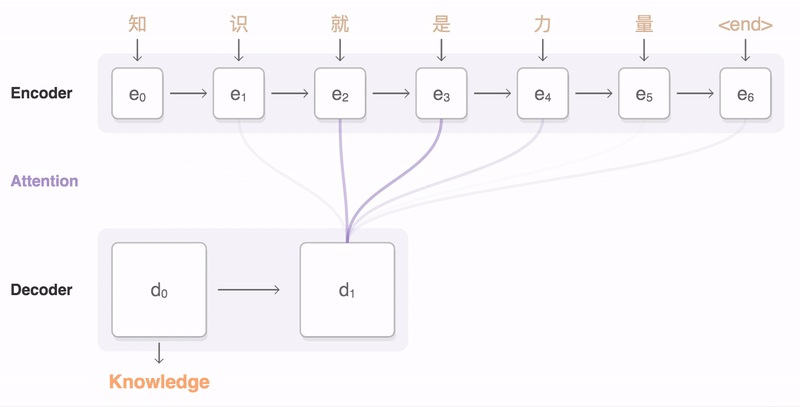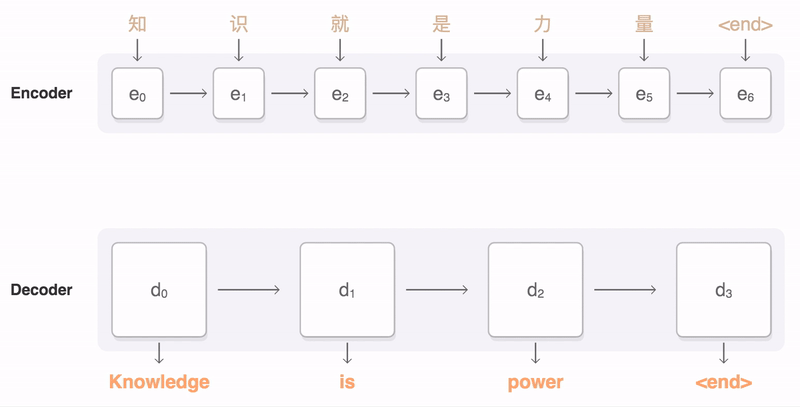
- 인코더와 디코더로 구성(두 개의 RNN 셀)
- 입력 시퀀스와 출력 시퀀스의 길이가 다를 수 있다고 가정
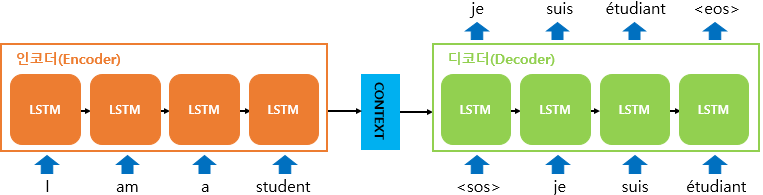
① 인코더(Encoder)
- 입력 문장을 받는 RNN 셀
- 모든 단어들을 순차적으로 받아 모든 단어 정보들을 압축하여 하나의 벡터 생성(context vector)
- context vector를 디코더(Decoder)로 전송, 이 벡터는 디코더 RNN 셀의 첫 번째 시점의 은닉 상태로 사용 됨
- 성능 문제로 바닐라 RNN이 아닌 LSTM 셀 또는 GRU 셀로 구성
② 디코더(Decoder)
- RNNLM(RNN Language Model)로서 context vector를 받아 번역된 단어를 한 개씩 순차적으로 출력하는 RNN 셀
- 다음에 올 단어를 예측하고, 그 예측한 단어를 다음 시점의 RNN 셀의 입력으로 넣는 행위를 반복(시작 심볼 <sos>부터 끝을 나타내는 심볼 <eos>가 올때까지)
- 훈련 과정과 테스트 과정의 작동 방식이 조금 다름
- 훈련 과정 : 정답을 알려주면서(교사강요 teacher forcing) 훈련
- 테스트 과정 : 정답 없이 테스트
- 입력된 시퀀스로부터 다른 도메인의 시퀀스를 출력하는 다양한 분야에서 사용되는 모델
- 입력 시퀀스와 출력 시퀀스를 각각 질문과 대답으로 구성하면 챗봇
- 입력 시퀀스와 출력 시퀀스를 각각 입력 문장과 번역 문장으로 만들면 번역기
- 내용 요약(Text Summarization), STT(Speech to Text) 등에 적용
2. 글자 레벨 기계 번역기(Character-Level Neural Machine Translation) 구현하기
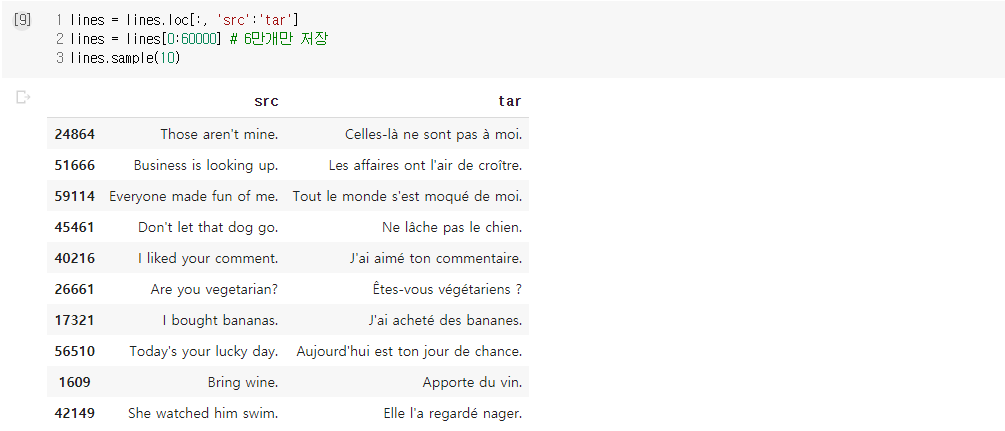
- 훈련 데이터로 두 개 이상의 언어가 병렬로 구성된 병렬 코퍼스(parallel corpus) 필요
- 프랑스 vs. 영어 병렬 코퍼스 다운로드 링크 : http://www.manythings.org/anki
- fra.txt 사용
- '영어 탭 프랑스어' 형식의 16만 개 샘플
1) 병렬 코퍼스 데이터에 대한 이해와 전처리










2) 교사 강요(Teacher forcing)
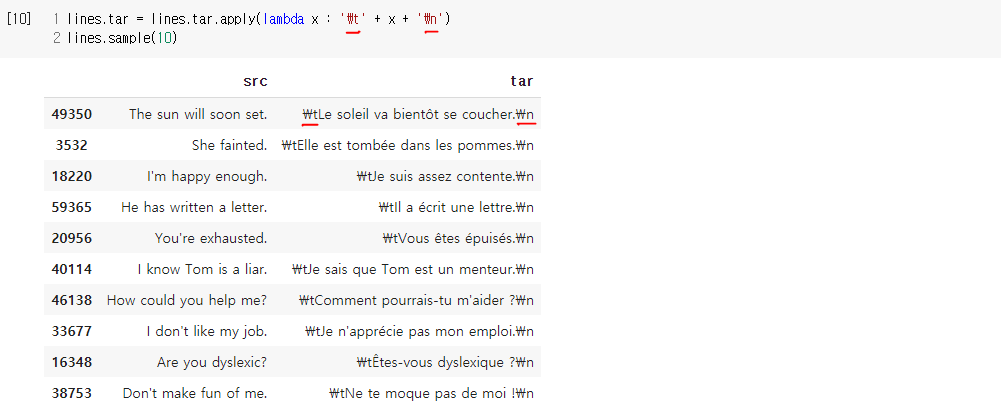
- RNN의 모든 시점에 대해서 이전 시점의 예측값 대신 실제값을 입력으로 주는 방법
3) seq2seq 기계 번역기 훈련시키기

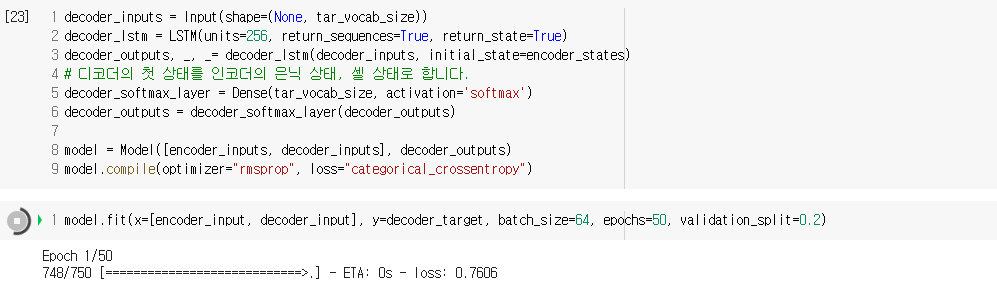
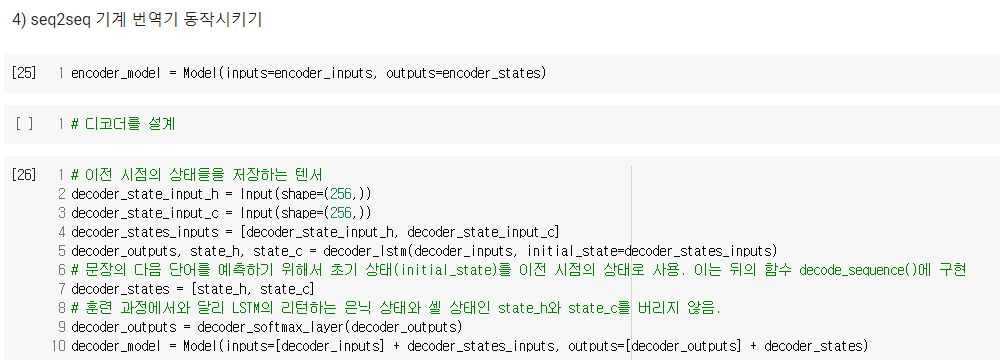
4) seq2seq 기계 번역기 동작시키기


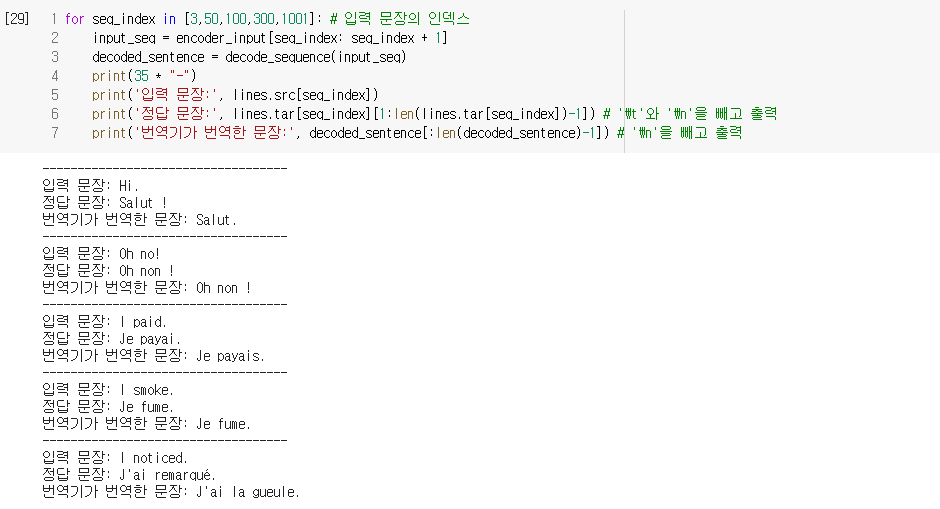
.ipynb
0.02MB
- 출처 : [딥러닝을이용한 자연어 처리 입문] 1501 시퀀스-투-시퀀스(Sequence-to-Sequence, seq2seq)
댓글
댓글 쓰기