[todaycodes오늘코드] [13/13] 청와대 국민청원 데이터로 파이썬 자연어처리 입문하기 - 머신러닝 fit, predict, evaluate 학습, 예측, 평가하기
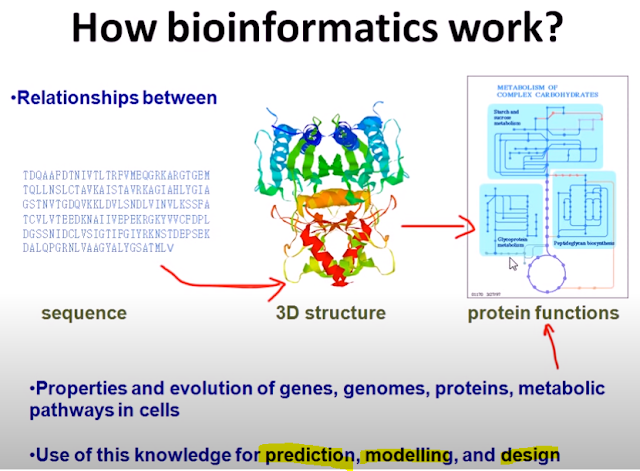
머신러닝(기계학습)으로 fit, predict, evaluate 학습, 예측, 평가하기 [청와대 국민청원 데이터로 파이썬 자연어처리 입문하기] 청와대 국민청원 사이트와 분석도구를 소개합니다. 2019년 2월 16일 토요일에 한국마이크로소프트 광화문오피스에서 진행된 LangCon 2019(Language Conference 2019) 튜토리얼 내용입니다. 해당 튜토리얼은 지난 해 데잇걸즈 2기와 파이콘 한국 2018에서 진행되기도 했습니다. * https://goo.gl/j9hEhj 에 가면 colab 노트북이 5번까지 있습니다. * colab 접근이 잘 되지 않는다면 크롬 앱스토어에서 "colaboratory"를 검색해서 설치하실 수 있습니다. 다음의 링크로 설치하실 수 있습니다. https://chrome.google.com/webstore/de... * 튜토리얼에 사용될 노트북은 파일 > 내 드라이브에 사본생성 으로 사본을 생성해 주셔야 실행권한이 부여됩니다. 1년 치 국민청원 텍스트 데이터를 전처리, 분석, 시각화(워드 클라우드, 단어 유사도) 해봅니다. 전처리한 텍스트를 바탕으로 평균보다 높은 투표수를 얻을지 낮은 투표수를 얻을지 머신러닝을 통해 예측해 봅니다. 또, 텍스트를 통해 어느 카테고리에 해당하는 내용인지도 예측해 봅니다. Colaboratory 사용을 위한 구글 이메일 주소와 개인 노트북이 필요합니다. 튜토리얼 노트북 참고 : https://github.com/corazzon/petitionW...
댓글
댓글 쓰기