[딥러닝을이용한 자연어 처리 입문] 1008 사전 훈련된 워드 임베딩(Pre-trained Word Embedding)
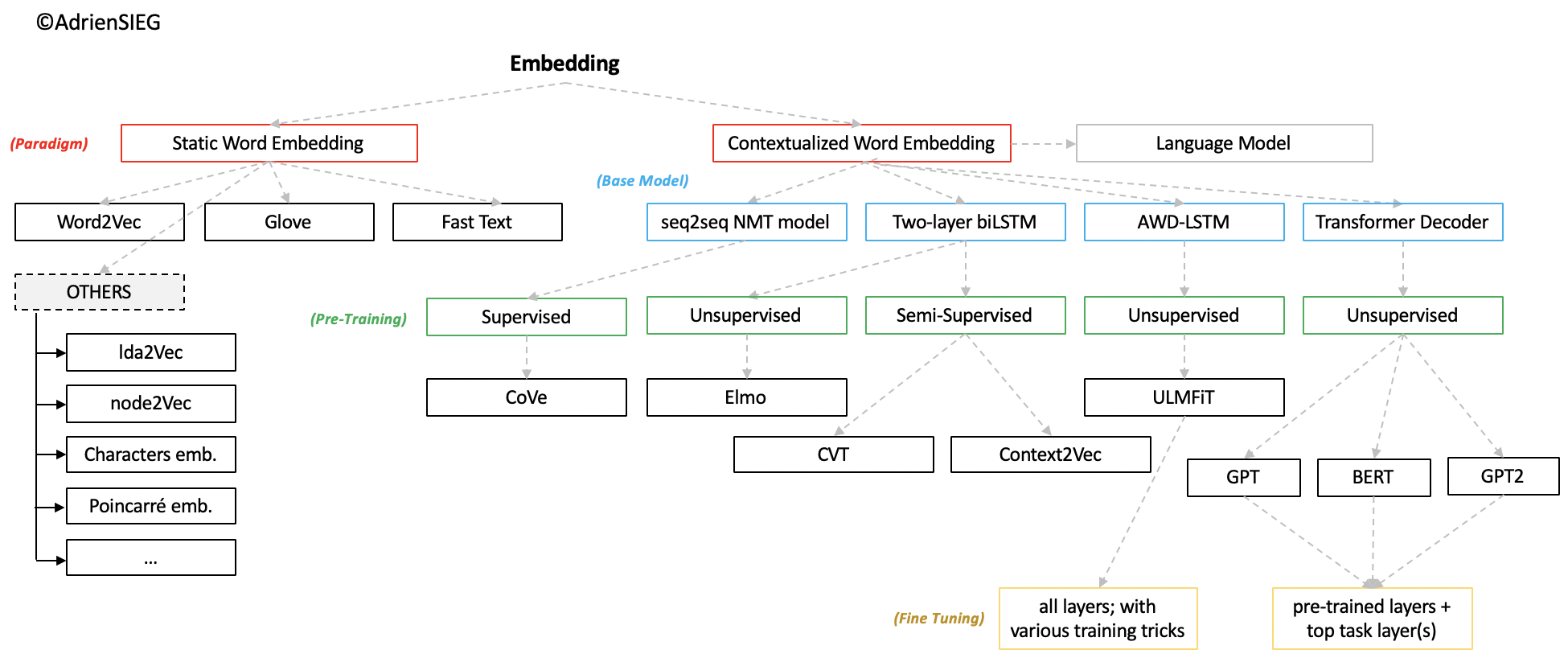
1. 케라스 임베딩 층(Keras Embedding layer)
1) 임베딩 층은 룩업 테이블이다
- 임베딩 층의 입력으로 사용하기 위해서 입력 시퀀스의 각 단어들은 모두 정수 인코딩이 되어있어야 함(어떤 단어 → 단어에 부여된 고유한 정수값 → 임베딩 층 통과 → 밀집 벡터)
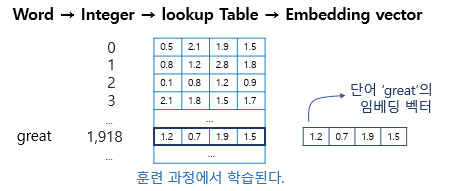
- 이 임베딩 벡터는 모델의 입력이 되고, 역전파 과정에서 단어 great의 임베딩 벡터값이 학습됨
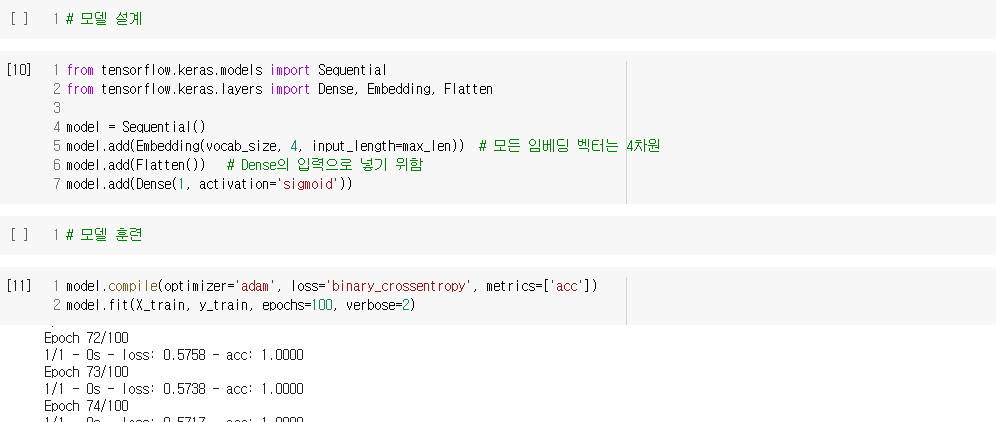
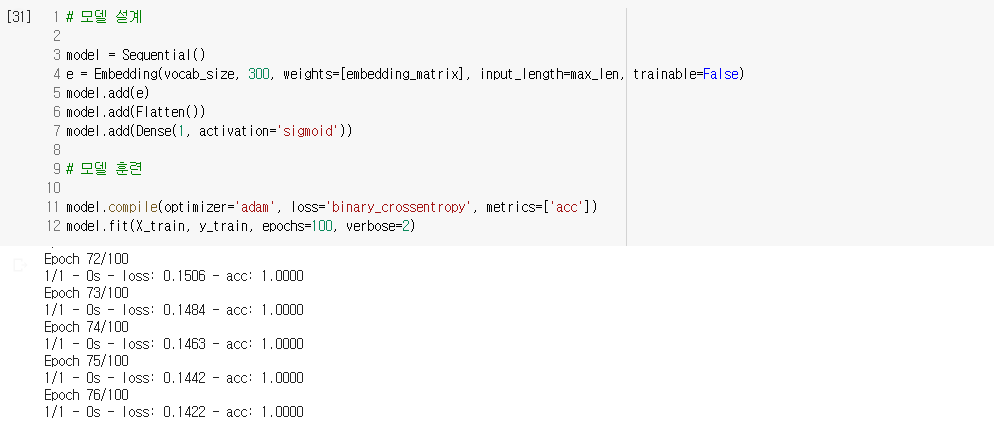
2) 임베딩 층 사용하기
- 문장의 긍, 부정을 판단하는 감성 분류 모델 만들기
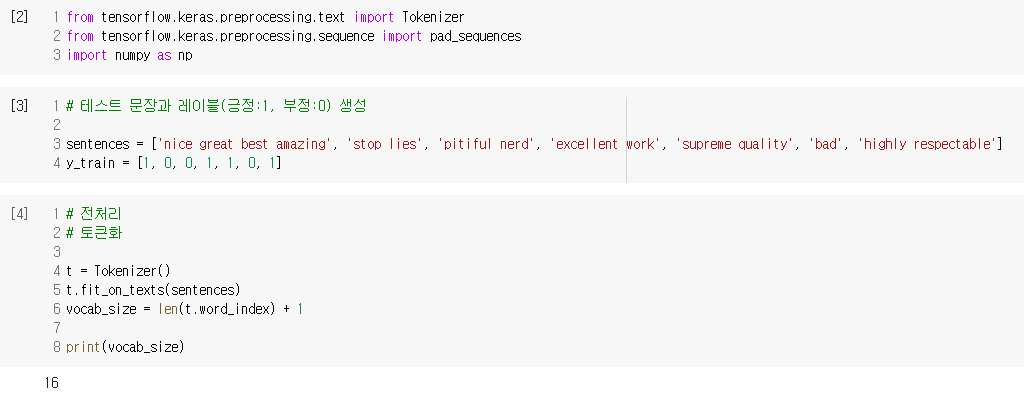

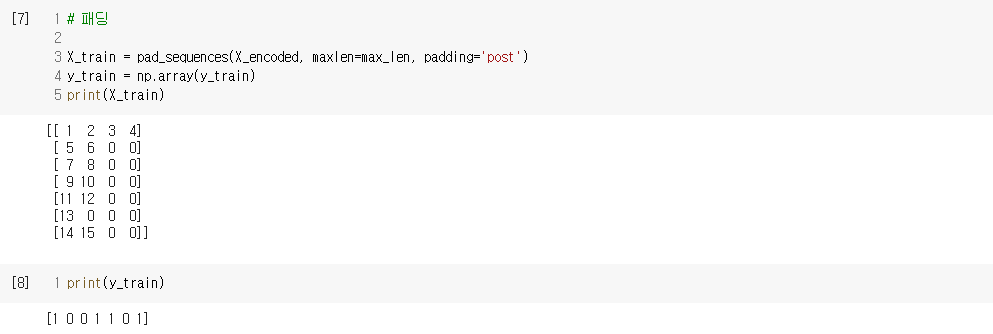
2. 사전 훈련된 워드 임베딩(Pre-Trained Word Embedding) 사용하기
- 훈련 데이터가 적은 상황이라면 모델에 케라스의 Embedding()을 사용하는 것보다 다른 텍스트 데이터로 사전 훈련되어 있는 임베딩 벡터를 불러오는 것이 나은 선택일 수 있음
- 훈련 데이터가 적다면 케라스의 Embedding()으로 해당 문제에 충분히 특화된 임베딩 벡터를 만들어내는 것이 쉽지 않습니다. 차라리 해당 문제에 특화된 임베딩 벡터를 만드는 것이 어렵다면, 해당 문제에 특화된 것은 아니지만 보다 일반적이고 보다 많은 훈련 데이터로 이미 Word2Vec이나 GloVe 등으로 학습되어져 있는 임베딩 벡터들을 사용하는 것이 성능의 개선을 가져올 수 있음
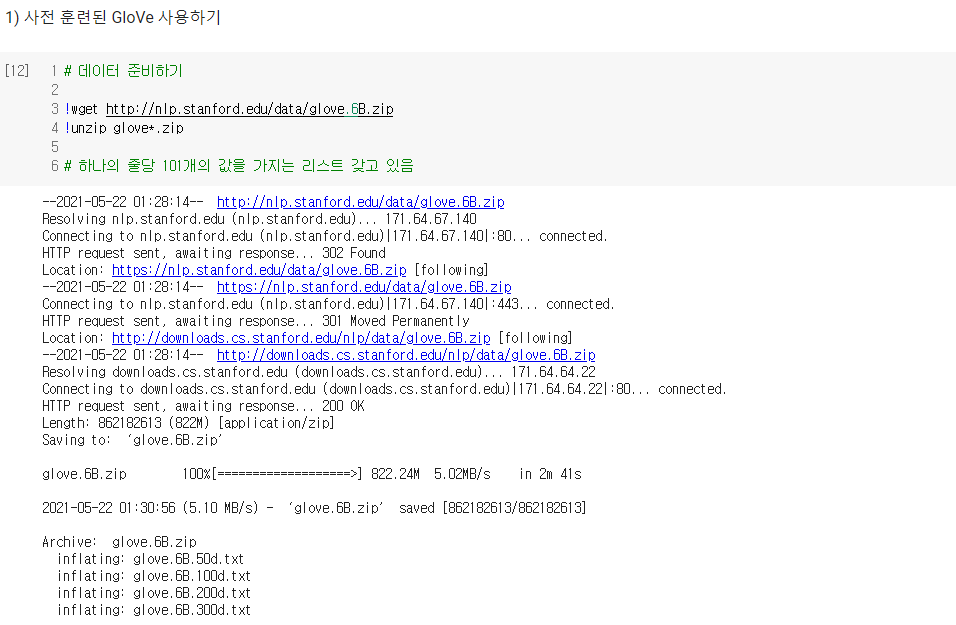
- GloVe 다운로드 링크 : http://nlp.stanford.edu/data/glove.6B.zip
- Word2Vec 다운로드 링크 : https://drive.google.com/file/d/0B7XkCwpI5KDYNlNUTTlSS21pQmM
1) 사전 훈련된 GloVe 사용하기


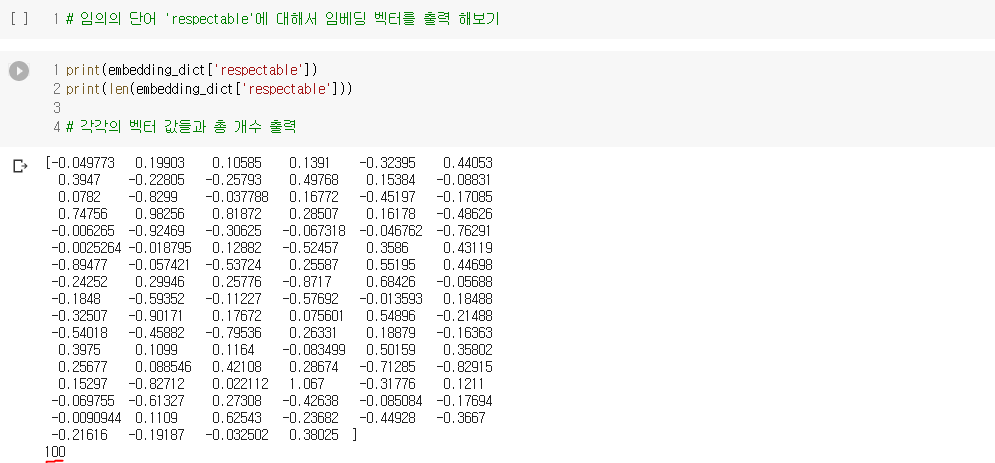

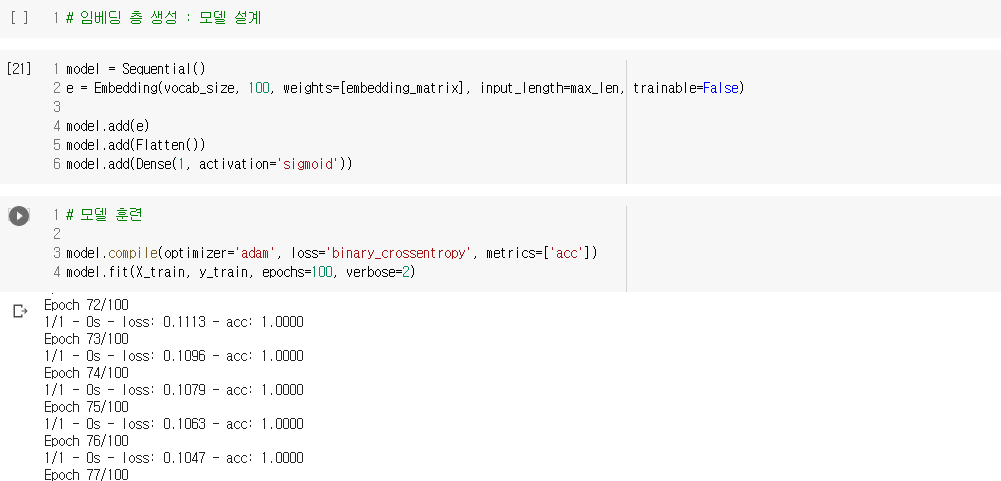
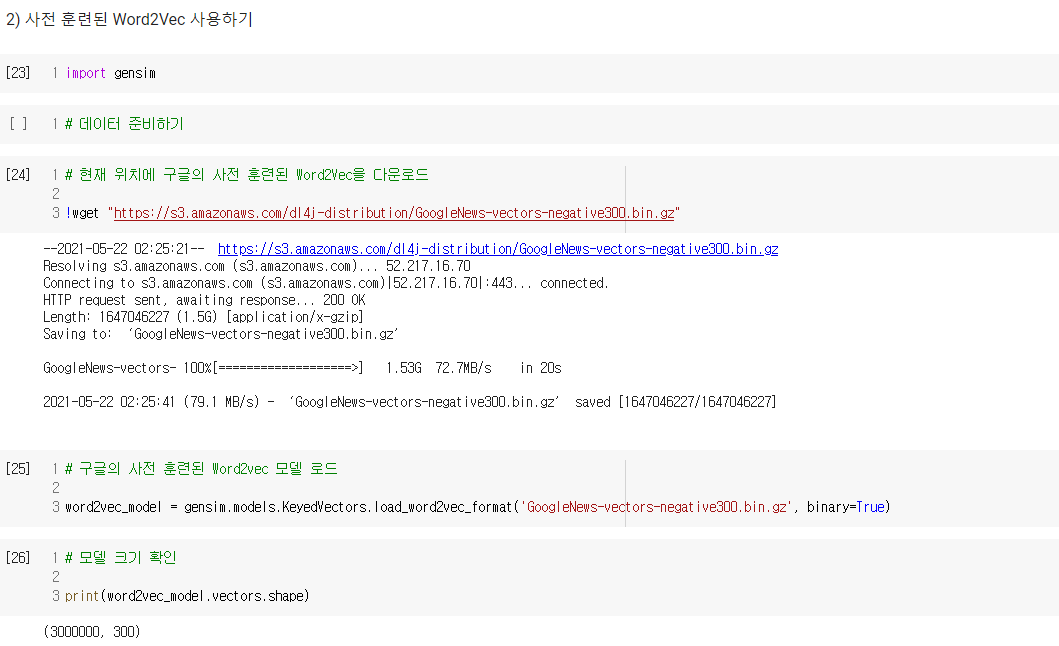
2) 사전 훈련된 Word2Vec 사용하기



.ipynb
0.01MB
- 출처 : [딥러닝을이용한 자연어 처리 입문] 1008 사전 훈련된 워드 임베딩(Pre_trained Word Embedding)
댓글
댓글 쓰기